在实际生产环境中,日志是我们排查错误的重要手段,好的日志系统可以让你的应用变得更加健壮。在用 C# 码代码的时候,别无二选的当然就是 Apache 的 Log4Net 。出乎我意料的是,Python 提供的日志功能更加方便,也更加容易上手,可以说是 SOC(关注点分离,Separation of concerns)的一个典范了。至于 logging 的具体设计规范,可以参考 PEP282。
logging 模块是 Python 提供的标准日志模块,它的优势在于:
- 对多线程支持
- 通过不同级别对日志进行分类
- 灵活性和可配置性
- 将如何记录日志与记录什么内容分离
logging 模块的组成
在 logging 模块中,持续在工作流中流转和处理的对象是 日志记录对象(LogRecord Objects),而在这个过程中大概有 4 个关键部分会对这个对象进行处理:
logger 记录器
logger 负责产生 LogRecord ,同时也是暴露给 application 来操作 LogRecord 记录的接口。logger 不能直接实例化,而是通过使用 module 级别的函数 logging.getLogger(name) 创建的,因此多个地方使用相同的 name 参数调用 getLogger 会返回同一个 logger 的引用。一般我们使用 logger = logging.getLogger 来产生 logger 然后通过类似 logger.info(f"Stock was sold at {price}) 这样的代码来产生 LogRecord 。
- 根据 PEP282 的 Final 标准,定义为 module 级别的函数目的在于不需要为了记录日志而将 logger 对象到处传递(*one does not have to pass logger object references around.*)
logger 分层
传递给 getLogger 的 name 参数中,可以用 . 分隔来定义一个层级,类似于 Python 的包层次结构,如 foo.bar ,foo.bar.baz 以及 foo.bam 都是 foo 的子级。
分层和 logger 的 propagate 参数相关:如果 propagate 的值是 True ,那么所有 logger 的 event 都会传递到它的父级 logger ,并作用于他们的 handler ,不管父级 Logger 的 level 以及 filter 设置。如果l propagate 为 False , 则日志消息不会传递给父级 logger 。
getChild(suffix) 方法可以返回指定 suffix 的子级 logger ,如 logging.getLogger('abc').getChild('def.ghi') 等同于 logging.getLogger('abc.def.ghi') 。这对于使用 __name__ 而不是字符串命名父级 logger 时较为有用。
logger 级别
logger 通过设置 level 阈值来控制是否处理某些级别的日志消息,注意因为 logger 可以包含多个 handler ,如果日志消息的严重级别达到或高于 logger 中某些 handler 的 level 同样也会被处理。 logger 创建时 level 的初始级别为 NOTSET (如果 logger 是 root logger 则可以处理任何的日志消息,否则就将消息传递给父级 logger )。注意,root logger 的默认 level 是 WARNING 。日志消息的级别表如下所示:
| 级别 | 数值 |
|---|---|
| CRITICAL | 50 |
| ERROR | 40 |
| WARNING | 30 |
| INFO | 20 |
| DEBUG | 10 |
| NOTSET | 0 |
- 注意,在 Python 3.2 版本中 setLevel(level) 的 level 参数可以使用字符串表示,但注意实际上内部还是以整型存储,可以看到 getEffectiveLevel() 以及 isEnableFor()等方法实际上还是要求传入整型或者返回整型结果。
logger 接口
logger 具有我们常用的和 level 级别一一对应的 debug(msg, *arg, **kwargs) 、 info(msg, *arg, **kwargs) 、 warning(msg, *arg, **kwargs) 、 error(msg, *arg, **kwargs) 、 critical(msg, *arg, **kwargs) 接口,还有更通用的 log(level, msg, *arg, **kwargs) 接口以及仅用于异常处理中的 exception(msg, *arg, **kwargs) 接口,后者会将异常信息添加到日志消息当中去。
注意,kwargs 中会检查四个关键字参数 exc_info 、 stack_info 、 stacklevel 和 extra 。
- 对
exc_info参数的求值不为False时,则会将异常信息添加到日志消息中,这通常是传入一个元组(格式类似于sys.exc_info()的返回)或者 exception 实例;否则会自行调用sys.exc_info()获取异常信息。 stack_info的值默认为False,如果为True则将堆栈信息也添加到日志消息中去,包括到 logging 被调用的过程。和exc_info不同的是,前者是记录从堆栈底部到当前线程中日志记录调用的堆栈帧 stack frame ,后者是在搜索异常处理程序时的异常跟踪记录。stacklevel默认为 1 ,如果大于 1 ,则日志事件在产生 LogRecord ,堆栈帧创建时会跳过对应数量的行号和函数名。extra是保留关键字参数,用于传递字典,这个字典可以填充到 LogRecord 的__dict__中,以供后续使用这些用户自定义属性。比如在 formatter 中定义了fmt='%(asctime)-15s %(clientip)s %(user)-8s %(message)s',那么可以在使用 logger 接口时传入:logger.warning("Problem: %s", "connection timeout", extra={'clientip': '192.168.0.1', 'user': 'fbloggs'})。
handler 处理器
handler 顾名思义,即负责处理 LogRecord 。标准的 logging 模块已经具备了多种内置的 handler :
| handler(处理器) | class defination(类型定义) | package(包位置) | describe(说明) |
|---|---|---|---|
| StreamHandler | StreamHandler(stream=None) | logging | 输出 LogRecord 到类似于 sys.stdout、sys.stderr 之类的流中,或者是任何的类文件对象(file-like object) |
| FileHandler | FileHandler(filename, mode=’a’, encoding=None, delay=False) | logging | 继承自 StreamHandler 输出功能,将 LogRecord 输出到硬盘文件中 |
| NullHandler | NullHandler | logging | Python 3.1 新增的 handler ,不会做任何的格式化或者输出操作,它本质上是个“空操作”,供库开发人员使用 |
| WatchedFileHandler | WatchedFileHandler(filename, mode=’a’, encoding=None, delay=False) | logging.handlers | 类似于 FileHandler ,只能用于 Unix/Linux 下,监控因 newsyslog 或 logrotation 等程序进行日志轮替而更改了日志文件时关闭并重新打开日志 |
| RotatingFileHandler | RotatingFileHandler(filename, mode=’a’, maxBytes=0, backupCount=0, encoding=None, delay=False) | logging.handlers | BaseRotatingHandler 的子类,根据磁盘文件大小进行日志轮替。必须同时设置 maxBytes 和 backupCount 同时不为零才能生效,当当前日志文件长度接近 maxBytes 时会发生日志轮替,同时给旧日志文件名补充从 .1 到 .backupCount 为扩展名,注意会被重复使用 |
| TimedRotatingFileHandler | TimedRotatingFileHandler(filename, when=’h’, interval=1, backupCount=0, encoding=None, delay=False, utc=False, atTime=None) | logging.handlers | BaseRotatingHandler 的子类,根据时间进行日志轮替。when 指定间隔类型,interval 指定间隔时间,轮替出来的旧日志文件会附加扩展名,扩展名取决于轮替间隔,一般使用 %Y-%m-%d_%H:%M:%S 。backupCount 不为 0 时则最多只保存 backupCount 份旧日志文件 |
| SocketHandler | SocketHandler(host, port) | logging.handlers | 输出 LogRecord 到网络套接字上,默认使用的是 TCP 套接字,如果不设置 port 则使用 Unix 域套接字 |
| DatagramHandler | DatagramHandler(host, port) | logging.handlers | 继承自 SocketHandler 输出功能,默认使用的是 UDP 套接字,如果不设置 port 则使用 Unix 域套接字 |
| SysLogHandler | SysLogHandler(address=(‘localhost’, SYSLOG_UDP_PORT), facility=LOG_USER, socktype=socket.SOCK_DGRAM) | logging.handlers | 输出 LogRecord 到远程或本地的 Unxi 系统日志当中(Unix syslog)。如果不设置 address ,则默认为 ('localhost', 514) ;同时默认使用 UDP 套接字,如果要使用 TCP 套接字(Windows 不支持)则需设置 socktype 为 socket.SOCK_STREAM |
| NTEventLogHandler | NTEventLogHandler(appname, dllname=None, logtype=’Application’) | logging.handlers | 支持输出 LogRecord 到本地的 Windows NT、Windows 2000 或者 Windows XP 的事件日志中,前提是你安装了 Python 的 Win32 扩展 ;appname 会显示在事件日志中,前提是要以此为名创建一个适当的注册表项目;dllname 应当给出定义了日志消息的 .dll 或 .exe 的完全限定名,默认为 win32service.pyd ;logtype 可选 Application 、 System 以及 Security |
| SMTPHandler | SMTPHandler(mailhost, fromaddr, toaddrs, subject, credentials=None, secure=None, timeout=1.0) | logging.handlers | 通过 SMTP 协议输出 LogRecord 到指定的一组电子邮箱地址;支持使用安全协议 TLS ,需提供身份凭证 |
| MemoryHandler | MemoryHandler(capacity, flushLevel=ERROR, target=None, flushOnClose=True) | logging.handlers | 是更为通用的 BufferingHandler 实现,允许将 LogRecord 缓冲到内存中,当超过 capacity 指定的缓冲大小,就会将日志 flush 到 target |
| HTTPHandler | HTTPHandler(host, url, method=’GET’, secure=False, credentials=None, context=None) | logging.handlers | 支持输出 LogRecord 到 Web 服务器上,支持 GET 和 POST 方法,当需要使用 HTTPS 连接时,则需要指定 secure 、 credentials 以及 context 参数 |
| QueueHandler | QueueHandler(queue) | logging.handlers | 支持输出 LogRecord 到队列中去,例如在 queue 以及 multiprocessing 中实现了的队列。日志记录可以在单独的线程中工作,这有利于在某些 Web 应用中,客户端线程需要尽快响应而任何潜在的慢操作可以在单独的线程上完成。其 enqueue(record) 方法默认使用队列的 put_nowait() 方法,当然你也可以 override 这个行为 |
| QUeueListener | QueueListener(queue, *handlers, respect_handler_level=False) | logging.handlers | 这个实际上不是 handler 但需要和 QueueHandler 协同工作。dequeue(block) 方法默认调用队列的 get() 方法,当然你也可以 override 这个行为 |
自 Python 3.6 开始,所有的 filename 参数都支持 Path 对象作为参数
formatter 格式化器
formatter 指定了 LogRecord 最终输出的形态。如果没有提供,默认使用 '%(message)s',这个值仅包含 LogRecord 调用时传入的消息。一般的格式器由 logging 库提供,其构造方法为 ft = logging.Formatter.__init__(fmt=None, datefmt=None, style='%'),然后占位符可以在一个 LogRecord 中声明所有属性;如果不指定 datafmt 则默认是 %Y-%m-%d %H:%M:%S 的样式。
| style 格式 | 说明 |
|---|---|
| %(name)s | logger 的名称 |
| %(levelno)s | 日志消息的级别,整型形式 |
| %(levelname)s | 日志消息的级别,文本形式 |
| %(pathname)s | 产生日志记录调用的源文件的全路径名 |
| %(filename)s | 上述全路径的文件名部分 |
| %(module)s | 产生日志记录调用的模块 |
| %(lineno)d | 产生日志记录调用的源文件的行号 |
| %(created)f | LogRecord 创建时间的时间戳(time.time()) |
| %(asctime)s | 日志产生的时间,默认格式为2018-01-08 16:32:45,896 |
| %(msecs)d | LogRecord 创建时间的毫秒部分 |
| %(relativeCreated)d | LogRecord 相对于加载日志模块时间(通常是在 application 启动时)的创建时间的时间戳 |
| %(thread)d | 线程ID |
| %(message)s | 具体的日志消息 |
filter 过滤器
filter 实际上是作为 logger.level 的补充,提供了更细粒度的工具,用于确定要输出哪些 LogRecord 。多种 filter 可以同时应用在 logger 和 handler 中。用户可以声明它们自己的 filter 作为对象,使用 filter 方法获取 LogRecord 作为输入,并提供 True/False 作为输出。一个 filter 的例子如下所示:
1 | class Filter: |
logging 流程图
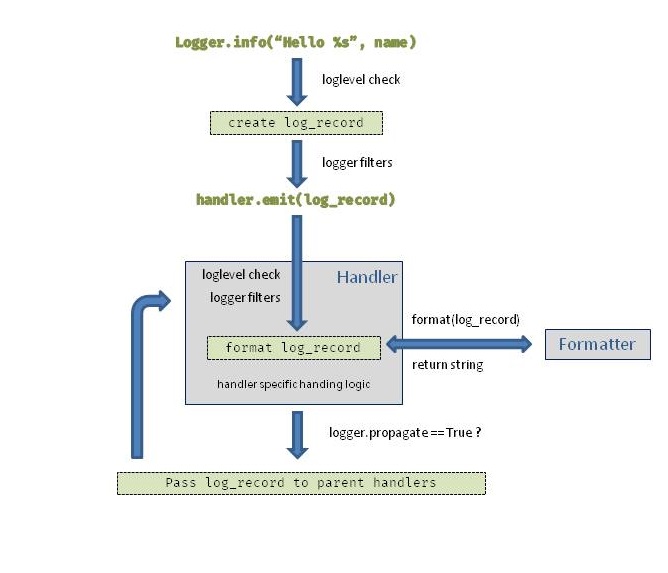
补充说明:
- logger 可以是残缺的,从而不允许任何记录从这被发出。
- 一个有效的层级可以同时在 logger 和 handler中被设置:举个例子,当一个 logger 被设置为 INFO 的等级,只要 INFO 等级及以上的才会被传递,同样的规则适用于 handler。
- formatter 只能被包含在 handler 中,不能被包含在 logger 中,并且只能有一个被包含在 handler 中。
logging 配置
logging 的配置可以采用 Python 代码或者是配置文件的形式处理。Python 代码的方式就是在应用的主模块中,构建 handler,filter,formatter 等对象。而配置文件的方式是将这些对象的依赖关系分离出来放在文件中。
基本配置 basicConfig
下面是一个最简单的设置:
1 | logging.basicConfig(level="INFO") |
这会搭建一个基础的 StreamHandler,这样就会在控制台上输出在 INFO 层级之上的任何 LogRecord 。下面是基础设置的一些参数:
| 参数 | 说明 | 举例 |
|---|---|---|
| filename | 指定创建的文件处理器,使用特定的文件名,而不是用流处理器 | /var/logs/logs.txt |
| format | 为处理器使用特定格式的字符串 | "'%(asctime)s %(message)s'" |
| datefmt | 使用特定的日期/时间格式 | "%H:%M:%S" |
| level | 为根记录器等级设置特定等级 | "INFO" |
| format | 和 file 函数意义相同,指定日志文件的打开模式 | 'w'或'a' |
| stream | 指定将日志的输出流,可以指定输出到 sys.stderr , sys.stdout 或者文件,filename 指定会覆盖 stream | sys.stderr |
注意,basicConfig 仅仅在运行开始会有效。如果你已经设置了根记录器,调用 basicConfig 将不会奏效。logging.getLogger() 直接不带参调用产生的就是 根记录器。
字典配置 dictConfig
可以用字典来说明元素的设置。这个字典应当由不同的部分组成,包括logger、handler、formatter以及一些基本的通用参数。
例子如下:
1 | config = { |
当被引用时,dictConfig 将会禁用所有运行的记录器,除非 disable_existing_loggers 被设置为 False。这通常是需要的,因为很多模块声明了一个全局记录器,它在 dictConfig 被调用之前被导入的时候将会实例化。
文件配置 fileConfig
logging.conf 采用了模式匹配的方式进行配置,正则表达式是r’^[(.*)]$’,从而匹配出所有的组件。对于同一个组件具有多个实例的情况使用逗号‘,’进行分隔。
下面是一个配置的例子:
1 | #logger.conf |
这个文件同样可以命名为 *.ini 文件。
然后在代码中使用:
1 | import logging |
多模块使用 logging
前面提及,多次调用 logging.getLogger(name) 在 name 相同的情况下都会返回同一个 logger 的 reference,即便在多模块的情况下。所以多模块使用 logging 的正确姿势是在 主模块 main 中配置 logging,这个配置会作用于其他子模块,然后在子模块中通过 getLogger 即可获取到配置相同的 logger 对象。
注意事项
- 千万不要在模块层次获取 logger,除非
disable_existing_loggers被设置为False。因为你在模块层次创建了 logger,然后你又在加载日志配置文件之前就导入了模块。logging.fileConfig与logging.dictConfig默认情况下会使得已经存在的 logger 失效。所以,这些配置信息不会应用到你的 logger 上。你最好只在你需要 logger 的时候才获得它。 - 从 Python 2.7 开始,
fileConfg与dictConfig都新添加了disable_existing_loggers参数,将其设置为False,可以解决上面的问题。 - 通常,这些设置将会存储在一个 YAML 文件中,并且从那里设置。很多开发者会倾向于使用
dictConfig而不是使用fileConfig,因为它为定制化提供了更好的支持。
logging 的拓展
记录 JSON 日志
如果我们想要 JSON 记录,我们可以通过创建一种自定义格式化来记录 JSON,它会将 LogRecord 转化为 JSON 编码的字符串。
1 | # coding: utf-8 |
输出结果:
1 | { |
在 LogRecord 中添加额外的上下文
在格式化中,我们可以指定任何日志记录的属性。
我们可以通过多种方式增加属性,在这个例子中,我们用过滤器来丰富日志记录:
1 | # coding: utf-8 |
输出结果:(这样有效地在所有日志记录中增加了一个属性)
1 | 2 H1 |
- 注意这会影响到应用中的所有 LogRecord ,包含你可能用到的库或者框架。它可以用于记录类似于在所有日志行里的一个独立请求ID,去追踪请求或者去添加额外上下文。
- 从 Python 3.2 开始,可以使用
setLogRecordFactory或者构建 LoggerAdapters Object 来添加额外上下文,详细戳我。
个人小结 + Q&A
当时我了解到 logging 标准模块的时候,感觉这个模块应该是最让我惊艳的一个标准库了,以至于我后来在用 Python 的时候,在思路上都会不由自主的想模仿这样的一种设计,比如我司产品的登录模块等等。严格来说作为一个工程师,抑或是叫码农吧,我的资历还算是“初哥”(“菜鸟”的意思),经常会被日常自己所接触到别人的实现思路感到惊奇,好实践要吸收总结,反模式要知其然知其所以然,软件工程除了基础的扎实,还要依赖经验的积累,这个博客的意图也大致如此。
如果之后有小伙伴针对这篇 blog 有疑问,可以再评论中留言,如果的确是很有典型意义的,会在对应的 blog 最后加上自己的解答。