最近在看 Twitter 的 Snowflake 算法,打算用 Python 来自己实现一边这个 IdWorker ,源码是用 Scala 写的,但是也不难看懂大概逻辑,顺便回顾下 Python3 里头 bytes 的操作以及单例模式。
概述 Snowflake
Twitter 在把存储系统从 MySQL 迁移到 Cassandra 的过程中,由于 Cassandra 没有顺序 ID 生成机制,于是自己开发了一套全局唯一 ID 生成服务:Snowflake ,当然作为服务它依赖并实现了更多部分,比如 Scala 版的 Thrift Server 等,这里我们仅讨论当中核心的算法
IdWorker部分。
Snowflake 算法生成的是 64 位的 ID ,其位结构如下图所示(经典老图):
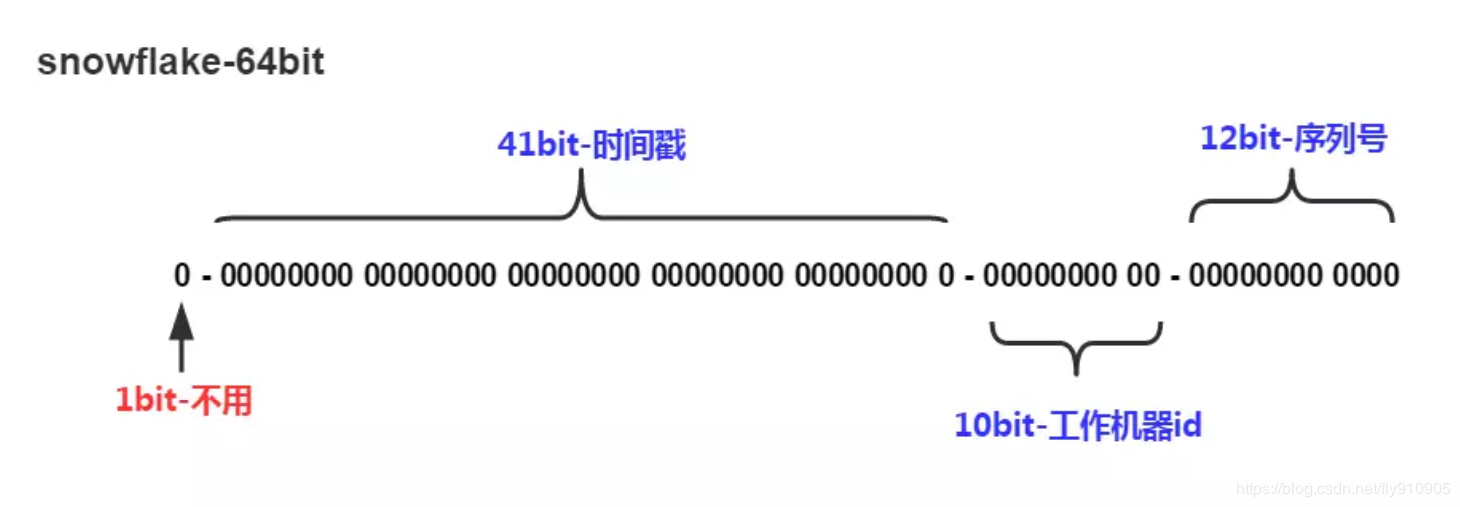
除去默认的首位 0 作为符号位,其余 63 位分别表示:
- 41 位毫秒级别精度的时间戳,一般都会减去一个起始时间时间戳
- 5 位数据中心 ID
- 5 位机器 ID
- 12 位的自增序列号,区别同毫秒内产生的 ID
Snowflake 实现
1 | import threading |
Tip1 Python3 中的 bytes
Snowflake 算法的特点是,用到了很多的位运算。位运算算是比较基础的计算机知识点,涵盖了诸如反码、补码、与或非异或等内容,对于 Python 而言,bit 和 byte 也是绕不开的一个点,甚至因为历史遗留问题可能还更加绕。
bytes 在计算机里头一般称为 字节 ,长度为 8 bit 。而 bytes 是 Python 3.x “新增”的不可变类型(Python 2 也有一个 bytes ,不过只是 str 的别名,可以在交互式敲入 bytes 看看输出什么东西 😁 ),目的就是为了解决 Python 2 中经常搞混人的 unicode 和 str 的问题(说实话这种设计在我认识的 programming language 中也是独树一帜了)。
可以将 Python 3 的
str简单理解为 Python 2 的unicode,但 Python 2 的str不能简单理解为 Python 3 的bytes,因为还有更贴切的bytearray类型。
我们所理解的二进制序列一般都认为是 01 序列,比如 01001001 这种样子。bytes 虽然也是表示二进制序列,但是它们的字面量在表示的时候是以 ASCII 文本的形式表示,这就意味着对于一个 byte 会有三种表示形式:
- 可以表示为 ASCII 字符的,就用 ASCII 字符本身;
- 制表符、换行符、回车符和其他的转义字符,就使用其转义序列
\t、\n、\r等。 - 其余无法直接表示的,就使用十六进制的转义序列表示(即以
\x开头的 8 位字节)
如我们生成的其中一个 ID 1268118639732232192 ,其二进制序列在 Python 中表示为 b'\x11\x99C/\x1eJ\x90\x00' ,其中 \x11 表示 00010001 ,而 \x99C 则表示 1001100101000011 ,等价于 \x99\x43 。
这种 ASCII 文本和十六进制转义序列混编的,确实非常考验眼力和心算(或者说记忆力也行)…… 当然可以直接用
bytes.hex()转为十六进制的形式就非常赏心悦目了。
对于 bytes 类型,使用 memoryview 来查看 bytes 的内存对象也是常见的做法(当然不止可以用于 bytes,所有支持缓冲区协议的对象都可以)。
因为 bytes 和 str 的关系如此紧密,我们都很熟悉 bytes 和 str 之间通过 encode 和 decode 之间进行转化,对于 int 类型,转换为 bytes 可能就不是太熟悉,虽然也是查 document 的事情:
int.bit_length()—— 返回以二进制表示一个整数所需要的位数,不包括符号位和前面的零int.to_bytes(length, byteorder, *, signed=False)—— 返回表示一个整数的字节数组,其中- int 会用
length个字节表示,如果不够长则会引发OverflowError(建议可以先调用bit_length获取所需长度ceil(bit_lenght/8)) byteorder参数确定用于表示整数的字节顺序,分为大端序(big)和小端序(little),要查看本机的字节顺序可以使用sys.byteordersigned表示是否使用 2’s complement number (中文届俗称“补码”,关于这个 term 可以查看 wikipedia 和 1’s complement number 之间的关系)来表示整数,默认为False,意味着此时如果 int 为负,则会引发OverflowError异常
- int 会用
int.from_bytes(bytes, byteorder, *, signed=False)—— 返回由给定字节数组所表示的整数,参数含义同上。int.as_integer_ratio()—— 不详,3.8 新增。
补充点:
0x表示的是十六进制的整数型\x表示的是十六进制的转义字符
Tip2 Python 与单例模式
这里的 Snowflake 没有刻意去实现单例模式,在某些场景下,「单例模式」Singleton 看上去确实很棒,例如连接池、日志记录器、配置读取、全局缓存等。实际上「单例模式」Singleton 的争议一直都比较大的,这里简单聊聊单例模式和 Python 下的单例模式。
⚪ 什么是 Singleton
以下的概念性的内容来自于 维基百科 - Singleton Pattern
「单例模式」Singleton 是 Gang of Four 提出的二十三种设计模式中的一种,解决了以下问题:
- 如何保证一个类只有一个实例
- 如何轻易地访问类的唯一实例
- 类如何控制其实例化
- 如何限制一个类的实例数量
对于 Singleton ,必须实现的是:
- ensure that only one instance of the singleton class ever exists; and (保证单例类只能有一个实例对象)
- provide global access to that instance. (给该实例提供全局访问)
针对 Singleton Patter ,GoF 也描述了如何实现单例模式:
- 隐藏类的构造函数
- 定义一个公共(public)的静态方法(static method),例如
getInstance()来返回这个类的唯一实例
很明显这个设计模式是针对 Java 而言,毕竟 Python 的 class 既没有访问控制也没有所谓的 static ,因此在 Python 上实现 Singleton 一直都有不同的声音。
⚪ 关于 Singleton 的争议
Google Test Blog 有一篇 08 年的 blog 阐述了 Singleton Pattern 的问题所在:正是因为单例类的唯一实例需要提供全局访问,同时这个全局访问是可传递的(transitive),这意味着 object 上的 state 也是可全局访问的,这就导致了 implicit shared state —— 隐式的状态全局共享。
这个是缺陷吗?在某种情况下是的,但也存在例外,比方说 logger 日志记录器,因为它们不存在 effect side 的问题,即任何单例的 user 都不会影响到其他同样也用到这个单例的 user ,所以没有真正的共享状态,同时也完全体现了易于完成任务的模式优点;另一个就是避免共享 state ,例如 Java 的枚举类(这通常也是 Java 推荐的实现单例模式的做法),这样的做法就类似于全局常数,这个普遍都可以被开发者所接受。
在推行 TDD 和 Agile 的今天,因为 Singleton 和其使用者之间的紧密耦合导致它难以测试也是一个问题(来源自 WhySingletonsAreControversial.wiki )。
因此,在选择 Design Pattern 的时候,上下文是非常重要的,错误的选择 Design Patter 就会弄成 Anti-Pattern 。
⚪ 基于 module 的 Singleton
这里雪花算法的实现 pysnowflake.py 是通过在 module 中直接定义 variable 和 function (而不是使用 class)的方式实现单例功能。
Python 的 module 是天然的单例模式,因为 Python 在第一次 import module 的时候会执行 moudle 的代码并生成 .pyc 文件,再次 import 的时候不会 re-execute module 的代码而是直接加载 .pyc 文件。
比较常见的一种做法还有:
1 | class Singleton(object): |
1 | from module_singleton import singleton |
在 module 级别上实现单例模式是最简单有效的,但严格来说:
- 和单例模式的定义不相符合,但对 Python 而言,如果只使用静态/类方法,实在没有必要创建一个类;
- 尽管理论上 module 只会被引入一次,但是也会有例外 What could cause a python module to be imported twice? - Stack Overflow —— A Python module can be imported twice if the module is found twice in the path.
至于如果要实现 module 级别上的单例的继承,这个反倒有解决方案,详见 PEP 318 – Decorators for Functions and Methods。
⚪ 基于 Decorator 的 Singleton
1 | def singleton(cls): |
很明显,使用装饰器会比使用多重继承更为直观,将所有生成好的实例都放在一个名为 instances 的 Dict 中和单例类进行映射,每次在类初始化的时候都去检查这个 Dict 来决定是否实例化类。
问题也很明显,虽然通过 MyClass 创建得到的是真正的单例对象,但是 MyClass 已经蜕化为一个 function 而不是 class ,因此你不能直接调用类方法,即 :o = type(s4)(); s3 == o or s4 == o 返回 False 。
⚪ 基于 __new__ 的 Singleton
1 | class Singleton(object): |
使用基类 Singleton 并覆盖了 __new__ 的实现:使用 _instance 来表示唯一实例,每次都初始化类的时候都会先判断唯一实例是否已经存在。
它比基于 Decorator 的实现更为优秀的地方在于,它实现的是一个真正的单例类 (class) 而不是函数 (function) ,但是由于使用了多重继承,Singleton 的 __new__ 方法可能会被覆盖导致一些我们意想不到的行为。
同时,这个实现并不会阻止新实例的 __init__() 方法,如果任何 Singleton 的子类实现了 __init__ 方法,将导致使用相同的 self 来多次调用它(一种解决的思路是使用 Factory Pattern 来创建实例)。
对于基于 __new__ 的方法,Python 文档中有一个 Guido 的实现(基于 Python2):
1 | class Singleton(object): |
⚪ 基于 metaclass 的 Singleton
1 | class Singleton(type): |
metaclass 是更加 Pythonic 的一个做法,我们不是限制单例类的实例化而是直接从源头创建了一个单例类。Python 中的 class 也是对象,称为 类对象 ,可以通过元类 type 创建,过程中会调用 type 的 __call__ 方法,因此我们要做的就是重写 type 的 __call__ 方法。
显然如果你确实需要一个单例类,使用元类实现应该是最好的方法。
⚪ P.S. 并发安全问题
注意单例模式保证了单例类只会有一个全局访问的实例,但并不保证线程安全;因此对于临界区的操作(比如上面方法里头的 _instance 、 _instances 等)必要的时候需要加上锁 Lock 。所以在 Java 方面对于单例模式的描述,经常会提到 Double Check Lock (DCL) 来保证线程安全和随之带来的延迟加载。
⚪ 另一种思路: Borg Pattern
这个说法来自于 ActiveState 的一篇讨论 SINGLETON? WE DON’T NEED NO STINKIN’ SINGLETON: THE BORG DESIGN PATTERN (PYTHON RECIPE) ,认为应该使用 Borg 模式来共享状态(因此一般会归类到 Monostate 模式上),它关注的是状态而不是对象本身是否同属一个,也意味着,Borg Pattern 是允许子类化的:
1 | class Borg(object): |
诚然对于共享状态而言 Borg 模式更加优秀,因为共享状态对于单例来说更像是个副产物。单例模式另一个重要的作用是节省内存(对于没有 GC 的语言来说这可能更为重要),这是 Borg 没有体现的地方。
Tip3 对于时钟回拨的想法
在代码里,可以看到如果 timestamp 小于 last_timestamp 即当前时间戳上一次运行时间戳,将导致服务 unavailable 。
在原 Twitter Snowflake 的 README 上,也提到了强依赖系统时间的问题,建议是通过 NTP 服务来保证集群机器的时钟同步,比如 ntpd 或者 clockspeed 、 chrony 等(其中还提到了和 Dovecot 的冲突问题的解决方法),当然了即使使用了 NTP 做同步还是有可能导致秒级别的 time backwards 。
美团的 Leaf 的做法利用了 ZooKeeper ,放弃用 NTP 同步时间的方式而是结合 Zookeeper 注册节点系统时间,并自行统计全局的时间,节点定期(3s)上传自身系统时间,在发生时间回拨的时候:
- 不提供服务,等时钟周期追上
- 做一层重试,然后上报告警系统或者直接摘除节点并直接告警
当然了 ZooKeeper 保证了 CP ,因此高可用性上可能会有问题,看过有 blog 想过使用 Redis 替代 ZooKeeper ,这些都是看自己项目规模的实际需要了。