对于 Python 的 import 机制,一直以来感觉都一知半懂,尤其是对于 Python 这种非常 freestyle 的操作,在项目组织上没有什么固定的目录结构可言,如果部署或者打包的时候发生 import 出错或者失败,有时候确实会丈二和尚摸不着头脑,充其量就改改 sys.path 就完事了。但是这样的实现无疑是 ugly 的,要想明白 import 的工作原理,还是得好好地啃啃硬骨头。
所以这篇 blog 就这么来了,内容会包括:
- 模块和包的基本介绍
- 默认的 import 流程和常见的 hack 手段
- import 协议以及相关对象:finder、loader、importer 和 spec
- 两种 import hook
模块 module 与 包 package
什么是模块
典型的,一个 .py 后缀文件即是 Python 的一个模块。在模块的内部,可以通过全局变量 __name__ 来获得模块名。模块可以包含可执行的语句,这些语句会在模块 初始化 的时候执行 —— 当所在模块被 import 导入时它们有且只会执行一次。
什么是包
根据目前 PEP420 的提案,目前的 Python 实际上是有两种包的存在:正规包(regular Package) 以及 命名空间包(Namespace package)。
要注意的是,Python 的 package 实际上都是特殊的 module :可以通过导入 package 之后查看
globals()可知;实际上,任何带有__path__属性的对象都会被 Python 视作 package 。
- 正规包:
在 Python 3.2 之前就已经存在了的,通常是以包含一个__init__.py文件的目录形式展现。当 package 被导入时,这个__init__.py文件会被 隐式 地执行。 - 命名空间包:
根据 PEP420 的定义,命名空间包是由多个 portion 组成的 —— portion 类似于父包下的子包,但它们物理位置上不一定相邻,而且它们可能表现为 .zip 中的文件、网络上的文件等等。命名空间包不需要__init__.py文件,只要它本身或者子包(也就是 portion)被导入时,Python 就会给顶级的部分创建为命名空间包 —— 因此,命名空间包不一定直接对应到文件系统中的对象,它可以是一个 虚拟 的 module 。
导入系统
模块中的 Python 代码可以通过 import(导入)操作访问另一个模块内的代码。import 语句时调起导入机制的常用方式,但不是唯一方式。importlib.import_module() 以及内置的 __import__() 函数都可以调起导入机制。
import 语句实际上结合了两个操作:
- 搜索操作:根据指定的命名查找模块
- 绑定操作:将搜索的结果绑定到当前作用域对应的命名上
import 的 search 操作实际上是带参调用 __import__() 函数,而函数的返回值会用在 import 语句的绑定操作上。
直接调用 __import__() 只会执行模块查找,以及如果找到的话就创建模块。这会有一定的副作用,比如导入父包和更新各式各样的缓存(包括 sys.modules),而且绑定操作只有 import 语句才会做得到。
其他调起导入机制的行为(比如
importlib.import_module())有可能会绕过__import__()并使用自定义的方法来实现导入。
当一个模块被首次导入时,Python 会搜索该模块,如果找到就创建一个 module 对象并初始化;如果位找到则抛出 ModuleNotFoundError 异常。至于如何找到这些模块,Python 定义了多种的 搜索策略 (search strategy),而这些策略可以通过 importlib 等提供的各类 hook 来修改和扩展。
根据 Python 3.3 的 changlog 可知目前导入系统已完全实现了 PEP302 的提案,所有的导入机制都会通过
sys.meta_path暴露出来,不会再有任何隐式的导入机制。
去哪里找到模块/包
绝对导入和相对导入
Python 提供了两种导入机制:
- relative import 相对导入
- absolute import 绝对导入
其中,相对导入是 Python 2.5 之前的默认的导入方法,形式如下:
1 | # 可以看到,使用相对导入时只能采取 from ... import ... 的形式 |
绝对导入也叫做完全导入,在 Python 2.5 之后被完全实现,同时在 PEP8 中也提倡使用完全导入,它的使用方式如下:
1 | from pkg import foo |
值得注意的是,使用绝对导入,我们经常会遇到 —— 因为位置问题,Python 找不到相应的库文件从而抛出 ImportError 异常。
其中很常用的一个办法是,将当前工作目录添加到 sys.path 这个列表当中去(注意要在你实际 import 该模块或包之前)。
模块搜索路径
当我们要导入一个模块(比如 foo )时,解释器首先会根据命名查找内置模块,如果没有找到,它就会去查找 sys.path 列表中的目录,看目录中是否有 foo.py 。sys.path 的初始值来自于:
- 运行脚本所在的目录(如果打开的是交互式解释器则是当前目录)
PYTHONPATH环境变量(类似于PATH变量,也是一组目录名组成)- Python 安装时的默认设置
当然,这个 sys.path 是可以修改的(正如上文提到的一种解决办法)。值得注意的是,如果当前目录包含有和标准库同名的模块,会直接使用当前目录的模块而不是标准模块。
扩展 —— 使用 .pth 文件扩展搜索路径
如果不想修改 sys.path 的同时又想扩展搜索路径,可以使用 .pth 文件。首先该文件内容很简单,只需要补充你要导入的库的路径(绝对路径),一行一个;然后将该文件放到 特定的位置 ,Python 在加载模块时,就会读取 .pth 文件中的路径。
那么这个所谓的 特定位置 是哪里呢?我们可以通过 site 模块的 getsitepackages 方法得到:
1 | import site |
在 Windows 下,该位置一般是对应环境(或虚拟环境)的 site-packages 目录。
深入 import 搜索
当然,上文主要是涉及默认的导入机制中搜索操作的具体表现,搜索操作的结果会加入到 sys.modules 中并进行绑定操作。实际上,这些操作在 Python 中有一套更为复杂而规范的流程,以便我们可以更好的扩展这套机制的同时尽可能地实现兼容性。
为了开始搜索,Python 需要被导入模块(或者包)的完全限定名(fully qualified name)。这个名称可能作为 import 语句的参数得到,或者是从函数 importlib.import_module() 或 __import__() 的传参得到。
缓存 cache
在导入搜索开始前,会先检查 sys.modules ,它是导入系统的缓存,本质上是一个字典,如果之前已经导入过 foo.bar.baz,则将会包含 foo,foo.bar 以及 foo.bar.baz 键,其对应的值为各自的 module 对象。
导入期间,如果在 sys.modules 找到对应的模块名的键,则取出其值,导入完成(如果值为 None 则抛出 ModuleNotFoundError 异常);否则就进行搜索操作。
sys.modules是可修改的,强制赋值None会导致下一次导入该模块抛出MoudleNotFoundError异常;如果删掉该键则会让下次导入触发搜索操作。
注意,如果要更新缓存,使用 删除 sys.modules 的键 这种做法会有副作用,因为这样回导致前后导入的同名模块的 module 对象不是同一个。最好的做法应该是使用 importlib.reload() 函数。
查找器 finder 和加载器 loader
如果在缓存中找不到模块对象,则 Python 会根据 import 协议去查找和加载该模块进来。这个协议在 PEP320 中被提出,有两个主要的组成概念:finder 和 loader 。finder 的任务是确定能否根据已知的策略找到该名称的模块。同时实现了 finder 和 loader 接口的对象叫做 importer —— 它会在找到能够被加载的所需模块时返回自身。
Python 自带了一些默认的 finder 和 importer 。其中第一个知道 如何定位内置模块,第二个知道 如何定位 frozen 模块,第三个默认的 finder 会在 import path 中查找模块(即 path based finder)。
根据术语表,import path 是一个由文件系统路径或 .zip 文件组成的列表(也可以被扩展为任何可以定位的资源位置如 URL),被
path based finder(默认的元路径 finder)使用来导入模块。此列表通常来自sys.path,但对于子包来说也可能是其父包的__path__属性。
我们可以打印来看一下这三个 Importer 和 Finder :
1 | import sys |
finder 并不会真正加载模块。如果他能找到对应命名的模块,会返回一个 module spec,它实际上是 module 导入所需信息的封装,供后续导入机制使用来加载模块。
注意在 Python 3.4 之前 finder 会直接返回 loader 而不是 module spec,后者实际上已经包含了 loader 。
import hook
import hook 是用来扩展 import 机制的,它有两种类型:
- meta hook
- import path hook
meta hook 会在导入的最开始被调用(在查找缓存 sys.modules 之后),你可以在这里重载对 sys.path、frozen module 甚至内置 module 的处理。只需要往 sys.meta_path 添加一个新的 finder 即可注册 meta_hook 。
import path hook 会在 sys.path (或 package.__path__)处理时被调用,它们会负责处理 sys.path 中的条目。只需要往 sys.path_hooks 添加一个新的可调用对象即可注册 import path hook 。
元路径 meta_path
当无法从 sys.modules 中找到模块时,Python 会继续搜索 sys.meta_path 列表,列表中的 finder 会被依次用来查询是否知道如何处理这个命名的模块。
所有的 meta path finder 都必须实现 find_spec 方法(参考 importlib.abc.MetaPathFinder.find_spec),如果无法处理就返回 None;否则返回一个 spec 对象(即 importlib.machinery.ModuleSpec 的实例)。如果全部的 finder 都没有返回,将抛出 ModuleNotFoundError 异常并放弃导入。
find_spec(fullname, path, target=None)
以 foo.bar.baz 模块为例对 find_spec 进行说明
参数说明:
| 参数 | 说明 | 示例 |
|---|---|---|
| fullname | 被导入模块的完全限定名 | foo.bar.baz |
| path | 供搜索使用的路径列表,对于最顶级模块,这个值为 None;对于子包,这个值为父包的 __path__ 属性值 |
foo.bar.__path__ |
| target | 用作稍后加载目标的现有模块对象,这个值仅会在重载模块时传入 | None |
对于单个导入请求可能会多次遍历 meta_path,加入示例的模块都尚未被缓存,则会在每个 finder (以 mpf 命名)上依次调用
mpf.find_spec("foo", None, None)mpf.find_spec("foo.bar", foo.__path__, None)mpf.find_spec("foo.bar.baz", foo.bar.__path__, None)
Python 3.4 之后 finder 的
find_module()已被find_spec()所替代并弃用。
import 加载机制
下面的代码简要说明了 import 加载部分的过程:
1 | module = None |
以下是一些细节:
- 在 loader 执行
exec_module之前,需要将模块缓存在sys.modules:因为模块可能会导入自身,这样做可以防止无限递归(最坏情况)或多次加载(最好情况)。 - 如果加载失败,那么失败的模块会从
sys.modules中被移除。任何已经存在的模块或者依赖但成功加载的模块都会保留 —— 这和重载不一样,后者即使加载失败也会保留失败的模块在sys.modules中。 - 模块的执行是加载的关键步骤,它负责填充模块的命名空间。模块执行将会全权委托给 loader ,由 loader 决定如何填充和填充什么。
- 创建出来并传递给
exec_module执行的 module 对象可能和最后被 import 的 module 对象不一样。
loader 对象
loader 是 importlib.abc.Loader 的实例,负责提供最关键的加载功能:模块执行。它的 exec_module() 方法接受唯一一个参数 —— module 对象,它所有的返回值都会被忽略。
loader 必须满足以下条件:
- 如果这个 module 是一个 Python module(和内置模块以及动态加载的扩展相区分),则 loader 应该在模块的全局命名空间(
module.__dict__)中执行模块代码。 - 如果 loader 不能执行模块,应该抛出
ImportError异常。
Python 3.4 的两个变化:
- loader 提供
create_module()来创建 module 对象(接受一个module specobject 并返回moduleobject)。如果返回None,则由导入机制自行创建模块。因为 module 对象在模块执行前必须存在sys.modules中。 load_module()方法被exec_module()方法替代,为了向前兼容,如果存在load_module()且未实现exec_module, 导入机制才会使用load_module()方法。
module spec 对象
module spec 主要有两个作用:
- 传递 —— 可以在导入系统的不同组件,如 finder 和 loader 之间传递状态信息
- 模板(boilerplate)构建 —— 导入机制可以根据 module spec 执行模板加载操作,没有 module spec 则 loader 需要负责完成这个工作。
module spec 通过 module 对象的 __spec__ 属性得以公开,可以查看 ModuleSpec 获取更多信息。
1 | import requests |
导入相关的模块属性
在 _init_module_attrs 步骤中,导入机制会根据 module spec 填充 module 对象(这个过程发生在 loader 执行模块之前)。
| 属性 | 说明 |
|---|---|
__name__ |
模块的完全限定名 |
__loader__ |
模块加载时使用的 loader 对象,主要是用于内省 |
__package__ |
取代 __name__ 用于处理相对导入,必须设置!当导入包时,这个值和 __name__ 相同;当导入子包时,则为其父包名;为顶级模块时,应该为空字符串 |
__spec__ |
导入时要使用的 module spec 对象 |
__path__ |
如果模块为包,则必须设置!这个值为可迭代对象,如果没有进一步用途,可以为空,否则迭代结果应该为字符串 |
__file__ |
可选值,只有内置模块可以不设置 __file__ 属性 |
__cached__ |
为编译后字节码文件所在路径,它和 __file__ 的存在互不影响 |
在命名空间包出来之前,如果想实现命名空间包功能,一般是在包的
__init__.py中修改其__path__属性。随着 PEP420 的引入,命名空间包已经可以不需要__init__.py的这种操作了。
path-based-finder 基于元路径查找器
上文已经提到过,Python 默认自带了几个 meta path 的 finder ,其中之一就是 PathBasedFinder ,它负责搜索 import path 上的路径。
这个 finder 实际上并不知道如何进行 import ,它的工作只是遍历 import path 上的每一个条目,将它们关联到某个知道如何处理特定类型路径的 path entry finder(路径条目查找器)。
根据术语表,path entry finder 是由
sys.path_hook列表中的可调用对象返回的(前提是它知道如何根据特定路径条目找到模块)。
可以将 PathEntryFinder 看作 PathBasedFinder 的具体实现。实际上,如果从 sys.meta_path 中移除了 PathBasedFinder ,则不会有任何 PathEntryFinder 被调用。
path entry finder 路径条目查找器
PathBasedFinder 会使用到三个变量,它们会提供给自定义导入机制的额外途径,包括:
sys.pathsys.path_hookssys.path_importer_cache
包的
__path__属性也会被使用。
sys.path 是一个字符串列表,提供了模块和包的搜索位置。它的条目可以来自于文件系统的目录、zip 文件或者其他潜在可以找到模块的“位置”(参考 site 模块)。
由于 PathBasedFinder 是一个 meta path finder ,所以必须实现了 find_spec() 方法。导入机制会通过调用这个方法来搜索 import path (通过传入 path 参数 —— 它是一个可遍历的字符串列表)。
在 find_spec() 内部,会迭代 path 的每个条目,并且每次都查找与条目相对应的 PathEntryFinder。但由于这个操作会很耗资源,因此 PathBasedFinder 会维持一个缓存 —— sys.path_importer_caceh 来存放路径条目到 finder 之间的映射(虽然是这样子命名,但它存放的确实是 finder 对象而不是 importer 对象)。那么只要条目找到过一次 finder 就不会重新再匹配(你可以手动移除缓存条目来达到再次强制匹配的目的)。
如果缓存中没有对应路径条目的键,则会迭代 sys.path_hooks 中的每个 可调用对象。这些可调用对象都接受一个 path 参数,并返回一个 PathEntryFinder 或者抛出 ImportError 异常。
如果遍历完整个 sys.path_hooks 的可调用对象都没有返回 PathEntryFinder,则 find_spec() 方法会在 sys.path_importer_cache 中存入 None 并返回 None ,表示 PathBasedFinder 无法找到该模块。
大致的流程如图所示:
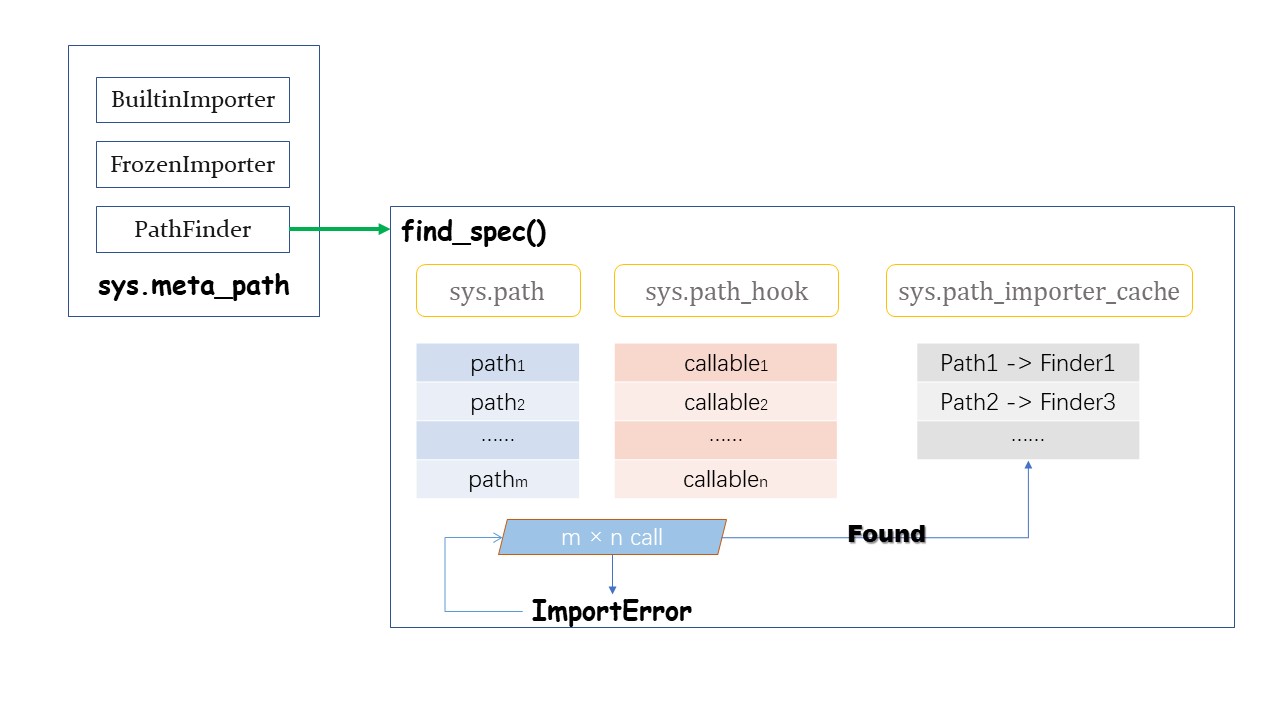
Path Entry Finder 协议
由于 PathEntryFinder 需要负责导入模块、初始化包以及为命名空间包构建 portion ,所以也需要实现 find_spec() 方法,其形式如下:
1 | find_spec(fullname, target=None) |
其中:
- fullname: 模块的完全限定名
- target:可选的目标模块
Python 3.4 之后
find_spec()替代了find_loader()和find_module(),后两者已被弃用。
注意,如果该模块是命名空间包的 portion ,为了向导入机制说明,PathEntryFinder 会将返回的 spec 对象中的 loader 设为 None 并将 submodule_search_locations 设置为包含这个 portion 的列表。
一个非常久远的例子
之前在阅读《Python 黑帽子: 黑客与渗透测试编程之道》的时候,里面提到了一个利用 GitHub 仓库作为木马远端控制的手段,木马程序通过 GitHub 交互来实现目标控制、更新木马以及上传被控端数据到 GitHub 仓库,其中最主要的是利用了 import hook 的技术(即 git_trojan 中的 GitImporter,是一个 meta path finder)。有兴趣的可以去 github 仓库查阅,仅供学习交流 😀。